
Machine Learning &
The WQ Map
enchancing precision RAS with ML
enchancing precision RAS with ML
"It’s difficult to make predictions -- especially about the future."
an old Danish proverb (and, for baseball fans, a Yogi-ism )
In the traditional modeling approach, we have data and a formula (or rules).
The formula tells us how to combine the data to calculate a result (or answers).
 (image from
seeedstudio.com
)
(image from
seeedstudio.com
)
An example: Suppose our focus is on the concentration of dissolved CO2. Well, there’s a formula (the rules) based on our understanding of chemistry that tells us how to combine temperature, salinity, pH, & alkalinity (the data) to compute dissolved CO2 (that’s the answer).
This traditional approach works well in steady-state systems described by simple formulae.
Real-world RAS, however, is far more complicated: there are many “moving parts” and we don’t understand their interactions well enough to write equations that adequately capture their full, non-steady-state behavior.
So, in the Real World, we have data — usually not all we want — but we do not have dependable formulae that use those data to produce accurate predictions.
The alternative is Machine Learning (ML).
In the ML approach, we have data and a result (answers) but — unlike the traditional approach — we do not have a formula (rules) connecting them.
 (image from
seeedstudio.com
)
(image from
seeedstudio.com
)
Why don’t we have a formula?
Because the system we want to control is too damned complex to be described accurately by nice, neat equations: We don’t know how to write (and solve) comprehensive rules that tell us how to use the input data to calculate the output result.
So...what do we do?
We train a machine learning model.
How?
In very general terms, there are four steps...
In this way, ML models learn to identify patterns in the data that relate the input to the output.
And once we have a well-trained ML model, we have a tool that can forecast the behavior of complex systems with an accuracy that far exceeds that of traditional models.
The ML paradigm calls to mind a much cited quote of iconic computer scientist Ken Thompson:
“When in doubt, use brute force.”
The ML approach continues to have wild success solving a wide variety of very complex real-world problems that cannot be solved with traditional modeling.
Among these...
...and humbling human contestants on Jeopardy.
That said, it's reassuring to understand that ML's success does not make a person's hard-earned aquaculture expertise obsolete.
"For all their hauntingly accurate results, deep learning algorithms are not the general intelligences of science fiction the public often perceives them to be. Today’s deep learning systems are nothing more than powerful inference systems that learn statistical correlations between their inputs and outputs." (see: here )
As noted below, a consequence of that frank admission is that flesh-and-blood aquaculturists remain essential for successful RAS management. ML models are another tool in the RAS digital toolbelt.
The following ML application very clearly underscores the difference between the two modeling approaches in a field — Physics — which, unlike RAS, enjoys well developed and time-tested formulae.
Princeton physicist Hong Qin [pronounced like “chin”] developed an ML model that predicts the orbits of planetary bodies in our solar system (see: here).
He trained the model with orbital data of Mercury, Venus, Earth, Mars, Jupiter, & Ceres (a large asteroid in the belt between Mars and Jupiter).
 The planets and Ceres (image from
Wikimedia Commons
)
The planets and Ceres (image from
Wikimedia Commons
)
He then used the trained model to correctly predict the orbits of other planetary bodies in the solar system, including their parabolic & hyperbolic escape orbits.
The kicker: The ML model was not programmed with Newton's Law of Motion & Law of Universal Gravitation — it didn’t “know” anything about them; it figured out the consequences of those laws on its own from the data.
(Take that, Copernicus and Kepler!)
"I would argue that the ultimate goal...is prediction," Qin said. "You might not necessarily need a law. "For example,
if I can perfectly predict a planetary orbit, [then] I don't need to know Newton's laws of gravitation and motion. "
Further: "Usually in Physics , you make observations [the data], create a theory based on those observations [the formulae], and then use that theory to predict new observations [the result ].”
In a nutshell, he described the traditional modeling approach outlined above.
He then said:
"...I'm...replacing this process with a type of black box that produces accurate predictions without using traditional theory..."
“Essentially, I bypassed all the fundamental ingredients of Physics .
“I go directly from data to data... There is no law of Physics in the middle.”
And that is the ML approach.
Hover over (on mobile, click) underlined segments in Qin's statements above to see the connection to aquaculture.]
The current version of the WQ Map has traditional stoichiometric relationships at the core of its chemical calculations. [Stoichiometry is the branch of chemistry that quantifies relationships among substances in a chemical reaction.]
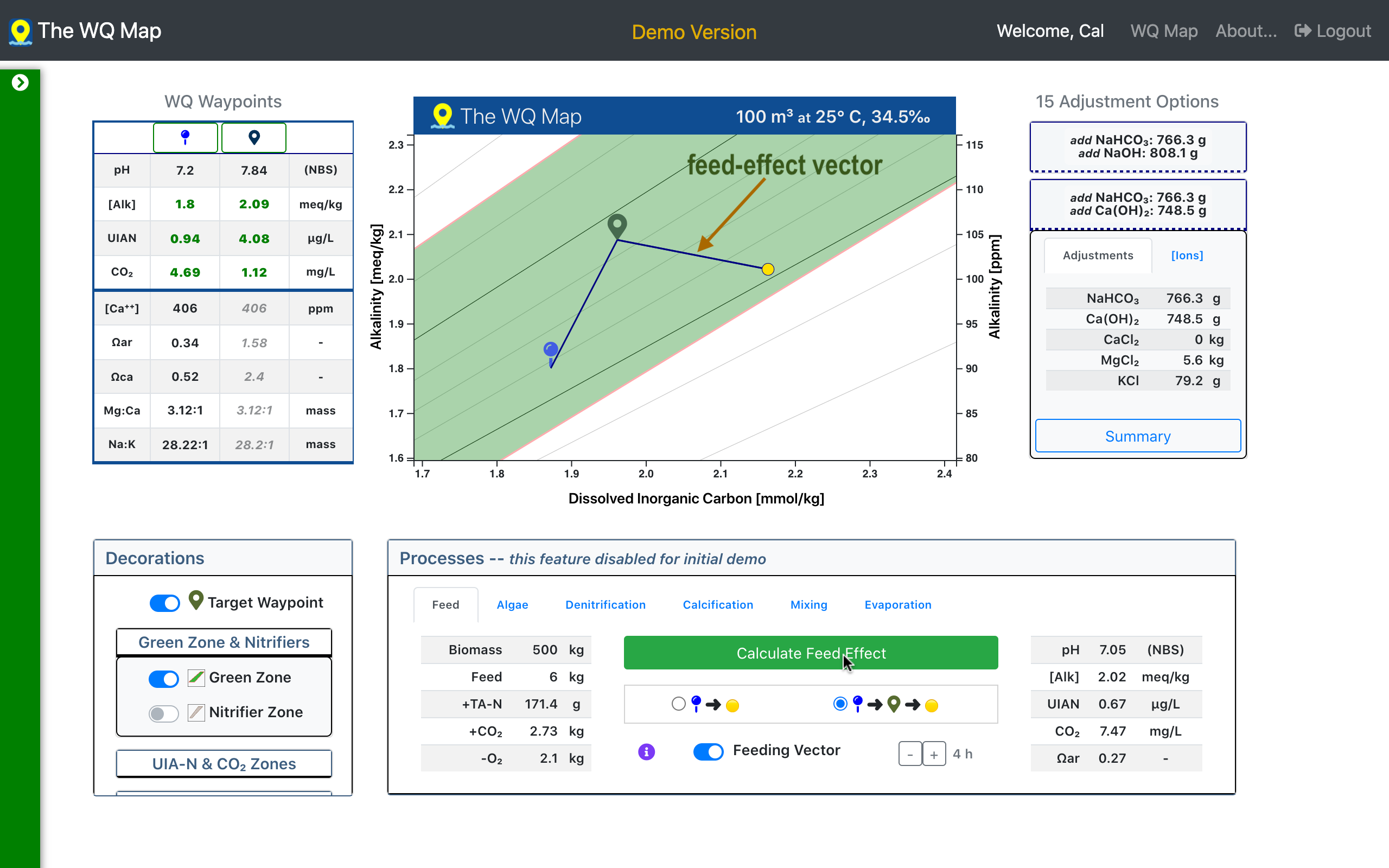 WQ Map with inital
& target
waypoints, and the feed-effect vector.
WQ Map with inital
& target
waypoints, and the feed-effect vector.
This traditional approach, as noted above, has a limited ability to characterize the complex web of dynamic, non-linear interactions that compose real-world RAS.
One way to take the WQ Map to the next level: An ML model that forecasts water quality & growth, given the most recent d days (or h hours) of sensor & sampling data.
Preferably, TinyML techniques would fit the model “at the edge” to avoid a round-trip to the Cloud for processing. (Beyond the added efficiency, this is essential in facilities with limited connectivity.)
Such a model might predict the effect of carbohydrate additions on water quality & biofloc aggregates, thereby helping to solve a critical management problem in RAS biofloc.
Additional ML applications that would enhance the WQ Map software package:
The road to upgraded RAS sustainability & profitability is paved with ML.
But there’s a barrier that blocks the path.
ML is a glutton for high-quality data, and data is the "critical infrastructure" at the foundation of robust machine learning models.
It’s not always feasible, however, to collect enough data to satisfy ML's appetite; and without sufficient data, model predictions suffer.
This generally is the case for RAS, as it takes 3 - 4 months to collect a time-series dataset for a single crop. Additionally, the cost of introducing realistic -- and potentially crop-threatening -- water-quality changes into a production tank (to train an anomaly-detection model) is unacceptably high.
When you don’t have (or otherwise are unable to collect) enough data to train a strong ML model, one possible remedy is data augmentation.
Similar to bootstrapping in Statistics, existing RAS datasets can be leveraged to produce synthetic data by using deep neural networks configured as Variational Auto-Encoders (VAE) or Generative Adversarial Networks (GAN).
With the success of ML in other fields and its potential to advance RAS operations, it's fair to ask...
Is there any room left for experienced aquaculturists?
The answer: Yes, of course. The aquaculturist still plays the central role in RAS management.
Besides supplying "the other ML" -- the Manual Labor that actually produces seafood -- the domain knowledge of experienced aquaculturists is an essential part of the ML workflow : collecting, processing, & curating the data on which the models feed, and interpreting the model output.
Maybe surprisingly, experienced RAS aquaculturists also have an important role in model development.
The most successful ML models are not only about deep math, but combine efficient machine-learning models with deep domain knowledge:
"Contrary to public belief, [driverless cars] are not powered by one massive monolithic model connecting sensors to steering wheel. Instead, their incredible capabilities are provided by a collage of specialized deep learning and hand-coded algorithms working in concert." (see: here )
In our case, the hand-coded rules will be based on the accumulated practical experience of RAS aquaculturists and certain stoichiometric features of RAS water chemistry.
If successful, we'll have a foundation for developing more robust software tools for recirc aquaculture management than presently available.
Such tools, in turn, would contribute to expanding local production of healthy, fresh-from-the-tank seafood in sustainable aquaculture systems for both subsistence and premium applications .
The current version of the WQ Map — the traditional stoichiometric version — remains a valuable tool that advances the state of aquaculture water-chemistry analytics.
Adding ML will extend the WQ Map's forecasting capabilities and equip aquaculturists with leading-edge software that improves RAS production and environmental sustainability.
The ML approach also opens the door for real-time, crop-specific predictions instead of static, one-size-fits-all stoichiometric predictions. That will significantly advance RAS water-quality management.